Linked List was developed in 1955 by Allen Newell, Cliff Shaw, and Herbert A. Simon at RAND Corporation. The Linked List is a dynamically-allocated data structure, meaning it grows dynamically in memory on its own very time-efficiently (as opposed to an Array List, for which we needed to explicitly reallocate memory as the backing array fills, which is a very time-costly operation).
A Linked List is a data structure composed of nodes: containers that each hold a single element. These nodes are "linked" to one another via pointers. Typically, we maintain one global head pointer (i.e., a pointer to the first node in the Linked List) and one global tail pointer (i.e., a pointer to the last node in a Linked List). These are the only two nodes to which we have direct access, and all other nodes can only be accessed by traversing pointers starting at either the head or the tail node.
In a Singly-Linked List, each node only has a pointer pointing to the node directly after it (for internal nodes) or a null pointer (for the tail node). As a result, we can only traverse a Singly-Linked List in one direction.

In a Doubly-Linked List, each node has two pointers: one pointing to the node directly after it and one pointing to the node directly before it (of course, the head and the tail nodes only have a single pointer each). As a result, we can traverse a Doubly-Linked List in both directions.

To access an arbitrary element in a Linked List, because we don't have direct access to the internal nodes (we only have direct access to head and tail), we have to iterate through all n elements in the worst case. If we are looking for the i-th element of a Linked List, this is a O(i) operation, whereas in an array, accessing the i-th element was a O(1) operation (because of "random access"). This is one main drawback of a Linked List: even if we know exactly what index we want to access, because the data is not stored contiguously in memory, we need to slowly iterate through the elements one-by-one until we reach the node we want.
Below is pseudocode for the "find" operation of a Linked List:
find(element): // returns True if element exists in Linked List, otherwise returns False
current = head // start at the "head" node
while current is not NULL:
if current.data == element:
return True
current = current.next // follow the forward pointer of current
return False // we iterated over all nodes but did not find "element"If we want to find what element is at a given "index" of the Linked List, we can perform a similar algorithm, where we start at the head node and iterate through the nodes via their forward pointers until we find the element we desire. Note that in the pseudocode below, we use 0-based indexing.
find(index): // returns element at position "index" of Linked List (or NULL if invalid)
if index < 0 or index >= n: // check for invalid indices
return NULL // we will use NULL to denote an invalid node
curr = head // looking for an element in the middle of the Linked List
repeat index times: // move forward index times
curr = curr.next
return currThe "insert" algorithm is almost identical to the "find" algorithm: you first execute the "find" algorithm just like before, but once you find the insertion site, you rearrange pointers to fit the new node in its rightful spot. Below is an example of inserting the number 5 to index 1 of the Linked List (using 0-based counting):
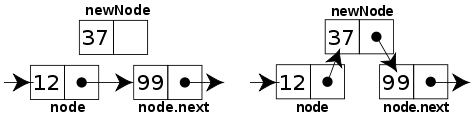
Notice how we do a regular "find" operation to the index directly before index i, then we point the new node's "next" pointer to the node that was previously at index i (and the new node's "prev" pointer to the node that is directly before index i in the case of a Doubly-Linked List, as above), and then we point the "next" pointer of the node before the insertion site to point to the new node (and the "prev" pointer of the node previously at index i to point to the new node in the case of a Doubly-Linked List).
Because the structure of a Linked List is only based on pointers, the insertion algorithm is complete simply after changing those pointers.
Below is pseudocode for the "insert" operation of a Linked List (with added corner cases for the first and last indices):
insert(newnode, index): // inserts newnode at position "index" of Linked List
if index == 0: // special case for insertion at beginning of list
newnode.next = head
head.prev = newnode
head = newnode
else if index == size: // special case for insertion at end of list
newnode.prev = tail
tail.next = newnode
tail = newnode
else: // general case for insertion in middle of list
curr = head
repeat index-1 times: // move curr to directly before insertion site
curr = curr.next
newnode.next = curr.next // update the pointers
newnode.prev = curr
curr.next = newnode
newnode.next.prev = newnode
size = size + 1 // increment sizeThe "remove" algorithm is also almost identical to the "find" algorithm: you first execute the "find" algorithm just like before, but once you find the insertion site, you rearrange pointers to remove the node of interest. Below is pseudocode for the "remove" operation of a Linked List (with added corner cases for the first and last indices):
remove(index): // removes the element at position "index" of Linked List
if index == 0: // special case for removing from beginning of list
head = head.next
head.prev = NULL
else if index == n-1: // special case for removing from end of list
tail = tail.prev
tail.next = NULL
else: // general case for removing from middle of list
curr = head
repeat index-1 times: // move curr to directly before removal site
curr = curr.next
curr.next = curr.next.next // update the pointers
curr.next.prev = curr
n = n - 1 // decrement n
In summation, Linked Lists are great (constant-time) when we add or remove elements from the beginning or the end of the list, but finding elements in a Linked List (even one in which elements are sorted) cannot be optimized like it can in an Array List, so we are stuck with O(n) "find" operations. Also, recall that, with Array Lists, we needed to allocate extra space to avoid having to recreate the backing array repeatedly, but because of the dynamic allocation of memory for new nodes in a Linked List, we have no wasted memory here.
Array-based and Linked data structures are two basic starting points for many more complicated data structures. Because one strategy does not entirely dominate the other (i.e., they both have their pros and cons), you must analyze each situation to see which approach would be better.